
Speech Synthesis dan Voice Cloning Ketika Suara Jadi Produk Digital
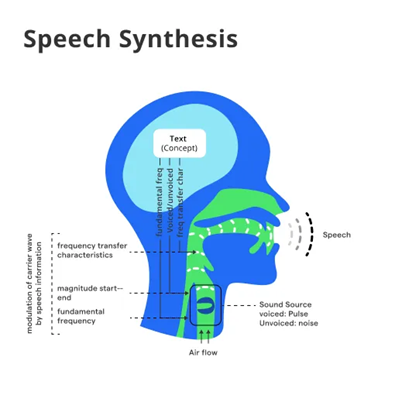 Figure 1. Diagram produksi suara sintetis dalam sistem speech synthesis (https://botpenguin.com/glossary/speech-synthesis)
Figure 1. Diagram produksi suara sintetis dalam sistem speech synthesis (https://botpenguin.com/glossary/speech-synthesis)
Coba bayangkan sebuah dunia di mana suara bukan lagi sekadar hasil pita suara manusia, tetapi sebuah produk digital bisa disalin, dimodifikasi, dikloning, bahkan diperjualbelikan. Dunia itu bukan masa depan jauh; itu adalah dunia yang kita jalani sekarang.
Kemunculan speech synthesis dan voice cloning membuat suara manusia berubah menjadi asset baru dalam ekonomi digital. Dari asisten virtual, audiobook, customer service, hingga konten kreator yang ingin menghemat waktu suara sintetis kini semakin mirip manusia, bahkan hamper tak terbedakan.
Kualitasnya meningkat begitu cepat sehingga kita berada di titik di mana “apakah ini suara asli?” sudah bukan pertanyaan yang sederhana lagi.
Speech Synthesis: Mesin yang Belajar Berbicara
Dulu, suara sintetis terdengar kaku seperti robot telepon operator. Namun dengan hadirnya deep learning, terutama arsitektur berbasis Transformer dan diffusion models, kualitas suara AI melonjak drastis. Speech synthesis modern biasanya mengikuti pipeline berikut:
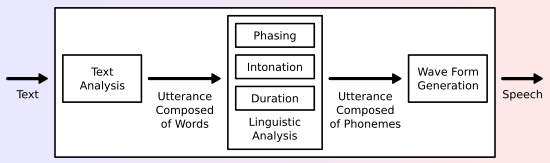
Figure 2. Alur umum Text-to-Speech (TTS) dari teks hingga audio (https://en.wikipedia.org/wiki/Speech_synthesis)
Pipeline dasar ini meliputi:
- Text Analysis: memecah kalimat, tanda baca, dan struktur bahasa.
- Linguistic & Prosody Modeling: menentukan intonasi, tekanan kata, durasi, ritme.
- Waveform Generation: vocoder seperti WaveNet, HiFi-GAN, atau VITS menciptakan audio berkualitas tinggi.
Model modern seperti Tacotron 2, FastSpeech 2, dan VITS2 mampu menghasilkan suara yang sangat natural, bahkan lengkap dengan napas, emosi, dan penekanan kata yang tepat.
Voice Cloning: Ketika Identitas Suara Bisa Disalin
Voice cloning melangkah lebih jauh bukan hanya membuat suara sintetis, tetapi mereplikasi suara manusia tertentu dengan akurat. Dulu proses ini membutuhkan rekaman panjang. Kini, teknologi zero-shot voice cloning dapat meniru suara seseorang dari 3–10 detik audio saja.
Platform dan riset utama:
- ElevenLabs
Salah satu platform paling realistis saat ini. Dipakai di film, game, dubbing, audiobook, bahkan customer service.
- OpenVoice (MIT + Microsoft)
Mampu mempertahankan intonasi, gaya bicara, bahkan emosi dengan presisi tinggi.
- Meta Voicebox
Model generasi berikutnya yang tidak dirilis publik karena kekuatan cloning-nya dianggap terlalu berpotensi disalahgunakan.
Dengan ini, suara berubah menjadi data, bukan lagi sekadar ekspresi manusia.
Mengapa Suara Menjadi Komoditas Digital?
- Industri Kreatif Berubah
Kreator konten dapat membuat narasi panjang tanpa harus merekam manual.
- Personalisasi AI Assistant
Pengguna dapat memilih suara yang sesuai karakter atau bahkan “menyimpan” suara mereka sendiri.
- Aksesibilitas
Penyandang disabilitas suara bisa memiliki suara digital yang mirip suara asli mereka sebelum kehilangan kemampuan berbicara.
- Efisiensi Bisnis
Perusahaan dapat mengotomatisasi layanan suara yang konsisten, murah, dan cepat diperbarui.
Suara menjadi asset bagian dari brand, identitas, bahkan properti digital.
Risiko dan Tantangan Etis
Sayangnya, semakin realistis teknologi suara, risiko penyalahgunaannya juga meningkat.
- Deepfake Suara
Penipuan melalui telepon, impersonasi tokoh publik, penggandaan suara keluarga semua ini sudah terjadi dalam skala dunia nyata.
- Pencurian Identitas Suara
Suara adalah biometrik. Jika digunakan tanpa izin, dampaknya setara pencurian wajah atau sidik jari.
- Manipulasi Emosi dan Opini Publik
Suara gampang memengaruhi persepsi seseorang. Deepfake suara dapat menjadi alat propaganda berbahaya.
- Hak Cipta & Kepemilikan Suara
Siapa yang memiliki suara kloning seorang aktor? Individu? Studio? Perusahaan AI? Regulasi dunia belum sepenuhnya siap.
Untuk itu, perusahaan besar mulai menerapkan beberapa mitigasi seperti AI Watermarking, system untuk mendeteksi audio deepfake, verifikasi identitas suara, serta pembatasan penggunaan model open-source. Tetapi ini baru awal dari perjalanan panjang etika AI suara.
Penutup
Saat ini kita memasuki era di mana suara bisa dikloning seperti menyalin file. Teknologi speech synthesis dan voice cloning memberi kreativitas yang luar biasa besar, tetapi juga menuntut tanggung jawab moral yang lebih besar.
Pada akhirnya, teknologi bukan hanya soal membuat mesin berbicara seperti manusia. Yang lebih penting adalah bagaimana kita melindungi suara manusia sebagai identitas, sebagai ekspresi, dan sebagai sesuatu yang tidak bisa digantikan oleh algoritma.
Karena dalam dunia digital yang semakin bising, suara yang paling berarti tetap suara manusia yang otentik.
Penulis:
Emmanuel Daniel Widhiarto, S.Kom – FDP Scholar
Referensi
BotPenguin. (2024). Speech Synthesis Glossary. https://botpenguin.com/glossary/speech-synthesis
Wikipedia. (2024). Speech Synthesis. https://en.wikipedia.org/wiki/Speech_synthesis
ElevenLabs. (2024). Voice AI Platform. https://elevenlabs.io